

-------by Hurkin
一直在咕咕咕,可能很久写一点点
Osint(信息收集/社工)
就是根据所得到的信息去网络上已公开的平台去搜索获得更多的信息,根据题目细嗦。
传统MISC
各种编码
base
base16编码
base16编码也称为十六进制编码或Hex编码,是一种将二进制数据表示为十六进制数字和字符的方法。它使用16个字符(0-9和A-F)来表示4位二进制数的每个组合。
编码原理:
由于4bit就可以表示2^4 = 16个字符。所以用4bit可以表示所有的十六进制数。
1byte=8bit 所以1byte = 两个十六进制数据。
这里就涉及一个字节序的问题:是用大端模式还是小端模式?Base16编码明确表明是用小端模式存储。
编码过程:
1.将二进制数据分割为4个一组
2.映射,将每四位二进制数据映射到对应的base16字符。如下:
0000 -> 0
0001 -> 1
0010 -> 2
0011 -> 3
0100 -> 4
0101 -> 5
0110 -> 6
0111 -> 7
1000 -> 8
1001 -> 9
1010 -> A
1011 -> B
1100 -> C
1101 -> D
1110 -> E
1111 -> F
3.编码
4.填充(可选):若二进制数据不是4的倍数,就在后面填充0;
base32编码
Base32编码是一种将二进制数据转换为使用32个不同字符表示的文本编码方式
由于5bit就可以表示2^5 = 32个字符。所以base32就是将二进制数据分割成5个一组,如果结尾不满足5的倍数,就用“=”填充,之后再根据base32索引表,进行编码。
base32索引表
00000 -> A 00001 -> B 00010 -> C 00011 -> D 00100 -> E 00101 -> F 00110 -> G 00111 -> H 01000 -> I 01001 -> J 01010 -> K 01011 -> L 01100 -> M 01101 -> N 01110 -> O 01111 -> P 10000 -> Q 10001 -> R 10010 -> S 10011 -> T 10100 -> U 10101 -> V 10110 -> W 10111 -> X 11000 -> Y 11001 -> Z 11010 -> 2 11011 -> 3 11100 -> 4 11101 -> 5 11110 -> 6 11111 -> 7
Base32编码通常用于需要在文本环境中表示二进制数据的场景,例如电子邮件中的附件编码、URL中的参数传递等。
base58编码
Base58编码是一种将二进制数据转换为文本编码的方法,通常用于表示加密货币地址和其他数据。
原理:
准备要编码的二进制数据: 将要编码的二进制数据准备好,通常是字节的形式。 添加版本前缀(可选): 在某些应用中,可以在二进制数据前添加一个版本前缀,以标识数据的类型或用途。这是可选的步骤,具体取决于编码的需求。 计算校验和(可选): 在某些情况下,可以计算二进制数据的校验和并附加到数据的末尾,以增加数据的完整性和安全性。这也是可选的步骤。 Base58编码: 将经过前两步(添加版本前缀和计算校验和,如果适用)的二进制数据转换为Base58编码的文本。编码过程如下: Base58字符集通常包括58个字符,通常是由除去易混淆的字符(如0、O、I和l)以及可能引起歧义的字符(如+和/)的字符集构成。 将二进制数据视为一个大整数,使用Base58字符集中的字符作为数字的基数。 将大整数除以58,记录余数,并继续除以58,直到商为零。这将生成Base58编码的每个字符。 最后,反转生成的字符顺序以获得最终的Base58编码字符串。 输出Base58编码: 最终得到的Base58编码字符串就是表示输入二进制数据的文本表示形式。
Base58编码的主要特点是它不包含易混淆的字符和可能引起歧义的字符,以增加可读性,并且在加密货币领域非常常见。请注意,Base58编码不是标准编码,不同的实现可能有略微不同的字符集和特殊规则。不同的加密货币可能会使用不同的Base58编码方案。
base58索引表:
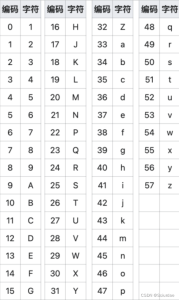
base64编码
Base64编码是一种将二进制数据转换为文本编码的方法,通常用于在文本协议中传输二进制数据,如电子邮件附件或在URL中传递数据。
原理:
准备要编码的二进制数据: 将要编码的二进制数据准备好,通常是字节的形式。 分组: 将二进制数据分成固定大小的组,每组通常为3字节(24位)。如果最后一组不足3字节,通常需要进行填充,以便每组都有3字节。 将每个组的二进制数据转换为十进制: 将每个3字节的二进制数据视为一个8bit*3=24bit位的二进制整数,再转化为一个十进制整数。 Base64编码: 将每个十进制整数编码为Base64字符。 Base64字符集通常包括64个字符,通常是大写字母A到Z、小写字母a到z、数字0到9以及两个额外的字符(通常是"+"和"/")。 以24位整数为例,将它分成4组,每组6位。这4组6位整数将被编码为4个Base64字符。 每个6位整数对应一个Base64字符,根据其在Base64字符集中的位置来选择。 如果原始数据不足3字节,会添加一个或两个额外的0位,以确保每个6位整数都有6位。 Base64编码的结果是一个文本字符串,其中包含一系列Base64字符,每4个字符分为一组,每组表示一个24位整数。 填充(可选): 如果原始数据的长度不是3的倍数,可以使用一个或两个填充字符“=”来补全Base64编码,以确保编码长度是4的倍数。
最终,Base64编码的结果就是表示输入二进制数据的文本字符串。在解码时,可以根据相同的算法将Base64编码的文本字符串还原为原始的二进制数据。
Base64编码是一种常见的数据表示方式,用于在各种情境中传输和存储二进制数据,因为它可以将二进制数据转换为纯文本,并且广泛支持各种编程语言和应用程序。
base64索引表:
| Index | Character | Index | Character | Index | Character | Index | Character | |:-------:|:-----------:|:-------:|:-----------:|:-------:|:-----------:|:-------:|:-----------:| | 0 | A | 16 | Q | 32 | g | 48 | w | | 1 | B | 17 | R | 33 | h | 49 | x | | 2 | C | 18 | S | 34 | i | 50 | y | | 3 | D | 19 | T | 35 | j | 51 | z | | 4 | E | 20 | U | 36 | k | 52 | 0 | | 5 | F | 21 | V | 37 | l | 53 | 1 | | 6 | G | 22 | W | 38 | m | 54 | 2 | | 7 | H | 23 | X | 39 | n | 55 | 3 | | 8 | I | 24 | Y | 40 | o | 56 | 4 | | 9 | J | 25 | Z | 41 | p | 57 | 5 | | 10 | K | 26 | a | 42 | q | 58 | 6 | | 11 | L | 27 | b | 43 | r | 59 | 7 | | 12 | M | 28 | c | 44 | s | 60 | 8 | | 13 | N | 29 | d | 45 | t | 61 | 9 | | 14 | O | 30 | e | 46 | u | 62 | + | | 15 | P | 31 | f | 47 | v | 63 | / |
需要注意的是上述base编码的索引表都是可以改变的。下面是一个base64换表的解密脚本
import base64 str1 = "cPQebAcRp+n+ZeP+YePEWfP7bej4YefCYd/7cuP7WfcPb/URYeMRbesObi/=" # 待解密的base64编码 string1 = "LMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/ABCDEFGHIJK" #替换的表 string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" print (base64.b64decode(str1.translate(str.maketrans(string1,string2))))
base85编码
Base85编码,也称为ASCII85编码,是一种将二进制数据转换为ASCII字符的编码方法。它通常用于在文本协议中传输二进制数据,尤其在Adobe的PostScript和PDF文件格式中使用。
原理:
准备要编码的二进制数据: 将要编码的二进制数据准备好,通常是字节的形式。 分组: 将二进制数据分成固定大小的组,每组通常为4字节(32位)。 将每个组的二进制数据转换为整数: 将每个4字节的二进制数据视为一个32位的二进制整数,然后将它转换为一个十进制整数。这个整数的范围通常是0到4294967295(2^32-1)。 Base85编码: 将每个十进制整数编码为Base85字符。 Base85字符集通常包括85个字符,通常是ASCII字符集中的可打印字符,除去易混淆的字符和可能引起歧义的字符。 以32位整数为例,将它分成5组,每组将被编码为5个Base85字符。 每个5个字符的组对应一个32位整数,根据其在Base85字符集中的位置来选择。 Base85编码的结果是一个文本字符串,其中包含一系列Base85字符,每5个字符分为一组,每组表示一个32位整数。 填充(可选): 如果原始数据的长度不是4字节的倍数,可以使用"z"字符作为填充字符,以确保编码长度是5的倍数。
base91编码
Base91编码是一种将二进制数据转换为文本编码的方法,通常用于在文本协议中传输二进制数据。与Base64相比,Base91编码具有更高的数据密度,但编码后的文本相对较长。
原理:
准备要编码的二进制数据: 将要编码的二进制数据准备好,通常是字节的形式。 分组: 将二进制数据分成固定大小的组,每组通常为3字节(24位)。如果最后一组不足3字节,可以进行填充。 Base91编码: 将每个3字节的二进制数据编码为Base91字符。 Base91字符集通常包括91个字符,通常是可打印ASCII字符集中的字符,除去易混淆的字符和可能引起歧义的字符。 以24位的二进制数据为例,将其分成4组,每组将被编码为4个Base91字符。 每个4字符的组对应一个24位的整数,根据其在Base91字符集中的位置来选择。 Base91编码的结果是一个文本字符串,其中包含一系列Base91字符,每4个字符分为一组,每组表示一个24位整数。 填充(可选): 如果原始数据的长度不是3字节的倍数,可以使用一或多个填充字符来确保编码长度是4的倍数
base100编码
base100是一种对称加密,加密后全是emoji表情。
总结
base家族编码都不算难,根据特征特点找到对应的加解密方式就可以了。下面总结一下各个base编码的特点。
base16特征:由大写字母(A-Z)和数字(0-9)组成,通常不需要“=”填充
base32特征:由大写字母(A-Z)和数字(2-7)组成,需要“=”填充
base64特征:大小写字母(a-Z)和数字(0-9)以及特殊字符('+','/')不满3的倍数用“=”补齐
base58特征:同base64相比,少了数字‘0’和字母‘O'数字’1‘和字母’I‘以及'+'和'/'符号,也没有“=”
base85特征:有很多奇怪的符号,但一般没有“=”
base91特征:由91个字符(0-9,a-z,A-Z,!#$%&()*+,./:;<=>?@[]^_`{|}~”)组成
base100特征:全是emoji表情。
XOR(异或)
-
如果两个对应位的值相同,结果为0。
-
如果两个对应位的值不同,结果为1。
类型
位异或
对两个二进制数的每一位进行异或运算。例如,对于二进制数1101和1011进行位异或处理,结果为0110。
字节异或
对两个字节(8位二进制数)的每一位进行异或运算。例如,对于十六进制数0xAB(二进制表示为1010 1011)和0xCD(二进制表示为1100 1101)进行字节异或处理,结果为0x66(二进制表示为0110 0110)。
字符串异或
对两个字符串的每个字符进行异或运算。例如,对于字符串"Hello"和"World"进行字符串异或处理,可以按照字符对应的ASCII码进行异或运算,得到结果"\x1d\x05\x0e\x0f\x1b"。
密钥长度不固定,可以短于密文
text = "Hello, World!"
key = "secret"
encrypted_text = xor_encrypt(text, key)
print("Encrypted:", encrypted_text)
decrypted_text = xor_decrypt(encrypted_text, key)
print("Decrypted:", decrypted_text)
数组异或
数组异或就是对数组中所有元素进行按位异或运算,具体步骤是先将数组元素逐个异或,最终结果就是数组的异或总和,比如数组[2 5 6]的异或总和是2 XOR 5 XOR 6 = 1。简单说就是相同为0,不同为1,按顺序算就行。
常见文件类型判断
拿到一个文件,先用010打开判断文件类型
图像文件
JPEG: (文件头 FF D8 FF), (文件尾 FF D9) TGA:未压缩: (文件头 00 00 02 00);RLE压缩: (文件头 00 00 10 00 00) PNG: (文件头 89 50 4E 47 0D 0A 1A 0A), (文件尾 AE 42 60 82) GIF: (文件头 47 49 46 38 39(37) 61), (文件尾 00 3B)
BMP: (文件头 42 4D) ICO: (文件头 00 00 01 00)AdobePhotoshop(PSD): (文件头 38 42 50 53)
压缩包文件
ZIP: (文件头 50 4B 03 04), (文件尾 50 4B) RAR: (文件头 52 61 72 21)
音频文件
Wave: (文件头 57 41 56 45) MIDI: (文件头 4D 54 68 64) AAC: (文件头 FF F1(9))
视频文件
AVI: (文件头 41 56 49 20) Real Audio: (文件头 2E 72 61 FD) Real Media: (文件头 2E 52 4D 46) MPEG: (文件头 00 00 01 BA(3)) Quicktime: (文件头 6D 6F 6F 76)
编码文件
XML: (文件头 3C 3F 78 6D 6C) HTML: (文件头 68 74 6D 6C 3E)
然后根据文件头文件尾,去判断文件尾部会不会存在各种奇奇怪怪的东西
文件分离
如果判断出来有存在多个对应的文件头和文件尾可以用binwalk或者formost分离
binwalk和foremost都是文件分离工具,但binwalk更常用于快速识别和分离文件,而foremost则在binwalk无法正确分离时使用,两者都能处理隐藏文件,但foremost有时更准确(有事没事都用用)
binwalk -e filename formost filename -o 输出的目录名
流量分析
键盘流量分析解题步骤
1.键盘流量
USB协议数据部分在Leftover Capture Data域中,数据长度为八个字节,其中键盘击健信息集中在第三个字节中。
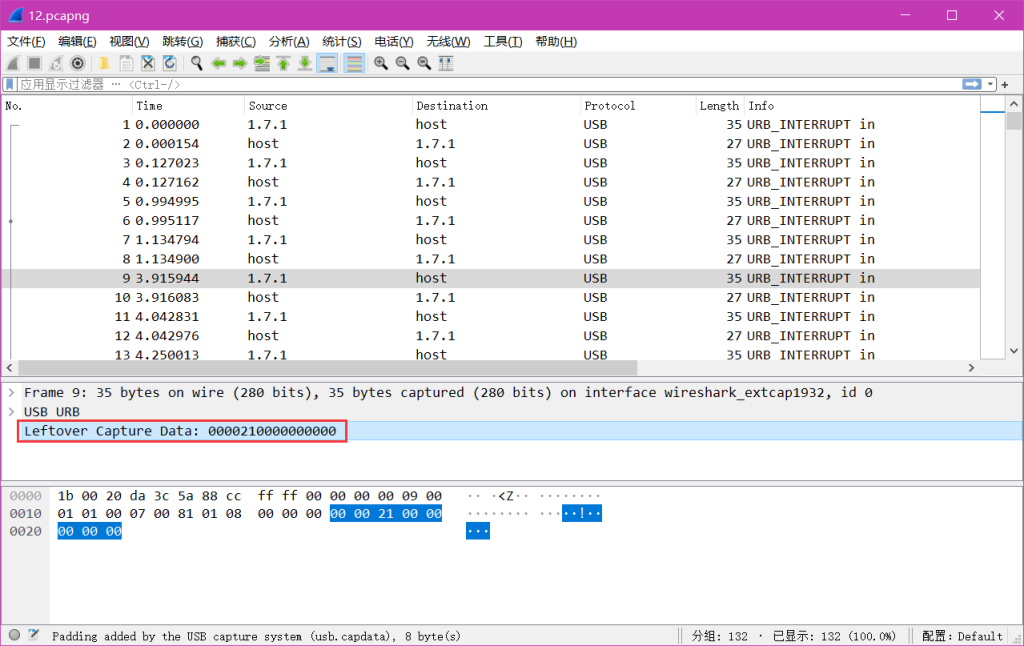
2.USB流量提取
USB协议的数据部分在 Leftover Capture Data 域中,可使用tshark提取流量
tshark -r xxx.pcapng -T fields -e usb.capdata > usbdata.txt

3.处理data文件,提取键盘信息
由于得到的USB文件中含有空行,常见的usbdata中以两字节加冒号的格式(如例子)。
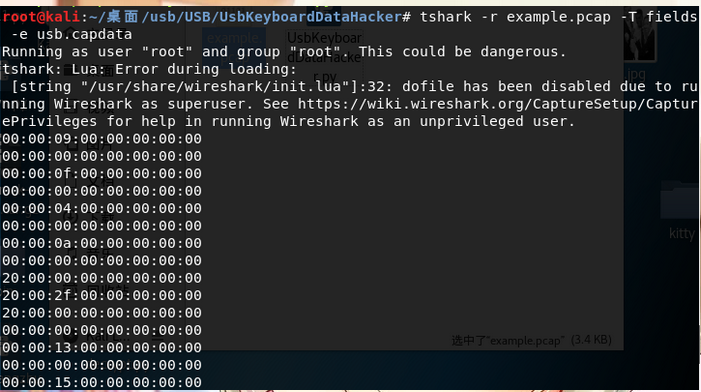
对文件进行处理:
#1.使用脚本删除空行
with open('usbdata.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
lines = filter(lambda x: x.strip(), lines)
with open('usbdata.txt', 'w', encoding='utf-8') as f:
f.writelines(lines)
#2.将上面的文件用脚本分隔,加上冒号;
f=open('usbdata.txt','r')
fi=open('out.txt','w')
while 1:
a=f.readline().strip()
if a:
if len(a)==16:#键盘流量的话len为16鼠标为8
out=''
for i in range(0,len(a),2):
if i+2 != len(a):
out+=a[i]+a[i+1]+":"
else:
out+=a[i]+a[i+1]
fi.write(out)
fi.write('\n')
else:
break
fi.close()
#3.最后用脚本提取
# print((line[6:8])) #输出6到8之间的值
#取出6到8之间的值
mappings = { 0x04:"A", 0x05:"B", 0x06:"C", 0x07:"D", 0x08:"E", 0x09:"F", 0x0A:"G", 0x0B:"H", 0x0C:"I", 0x0D:"J", 0x0E:"K", 0x0F:"L", 0x10:"M", 0x11:"N",0x12:"O", 0x13:"P", 0x14:"Q", 0x15:"R", 0x16:"S", 0x17:"T", 0x18:"U",0x19:"V", 0x1A:"W", 0x1B:"X", 0x1C:"Y", 0x1D:"Z", 0x1E:"1", 0x1F:"2", 0x20:"3", 0x21:"4", 0x22:"5", 0x23:"6", 0x24:"7", 0x25:"8", 0x26:"9", 0x27:"0", 0x28:"\n", 0x2a:"[DEL]", 0X2B:" ", 0x2C:" ", 0x2D:"-", 0x2E:"=", 0x2F:"[", 0x30:"]", 0x31:"\\", 0x32:"~", 0x33:";", 0x34:"'", 0x36:",", 0x37:"." }
nums = []
keys = open('out.txt')
for line in keys:
if line[0]!='0' or line[1]!='0' or line[3]!='0' or line[4]!='0' or line[9]!='0' or line[10]!='0' or line[12]!='0' or line[13]!='0' or line[15]!='0' or line[16]!='0' or line[18]!='0' or line[19]!='0' or line[21]!='0' or line[22]!='0':
continue
nums.append(int(line[6:8],16))
keys.close()
output = ""
for n in nums:
if n == 0 :
continue
if n in mappings:
output += mappings[n]
else:
output += '[unknown]'
print ('output :\n' + output)
PS,脚本可能因为设备型号有可能有变化
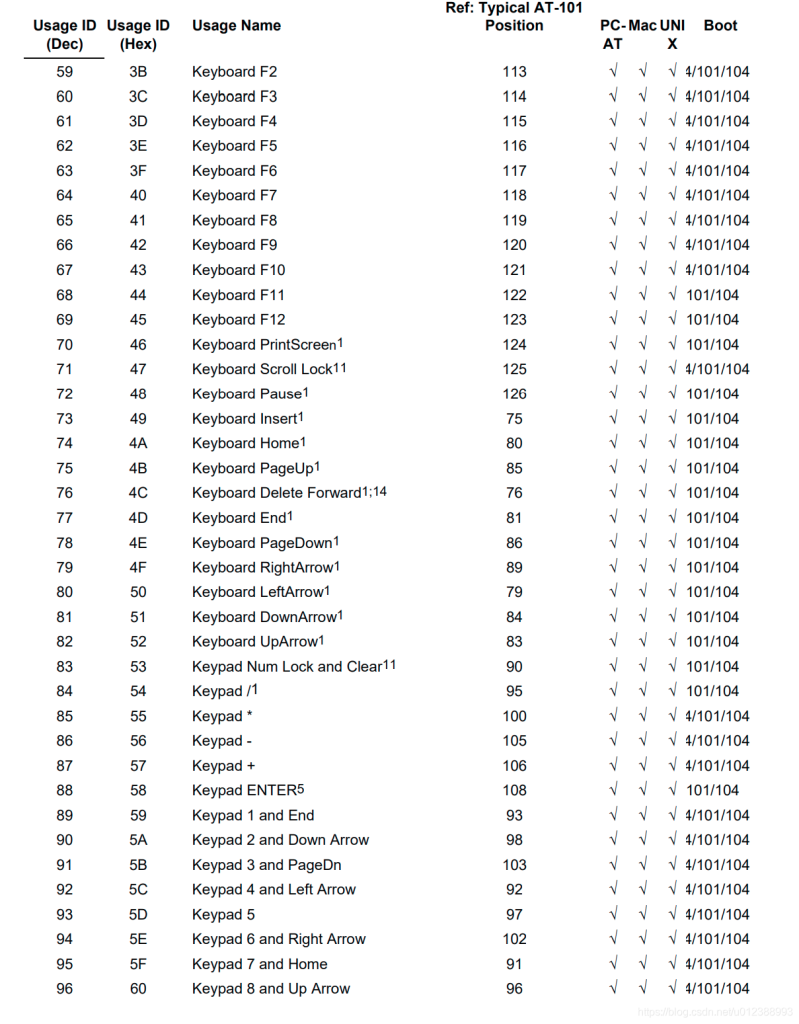
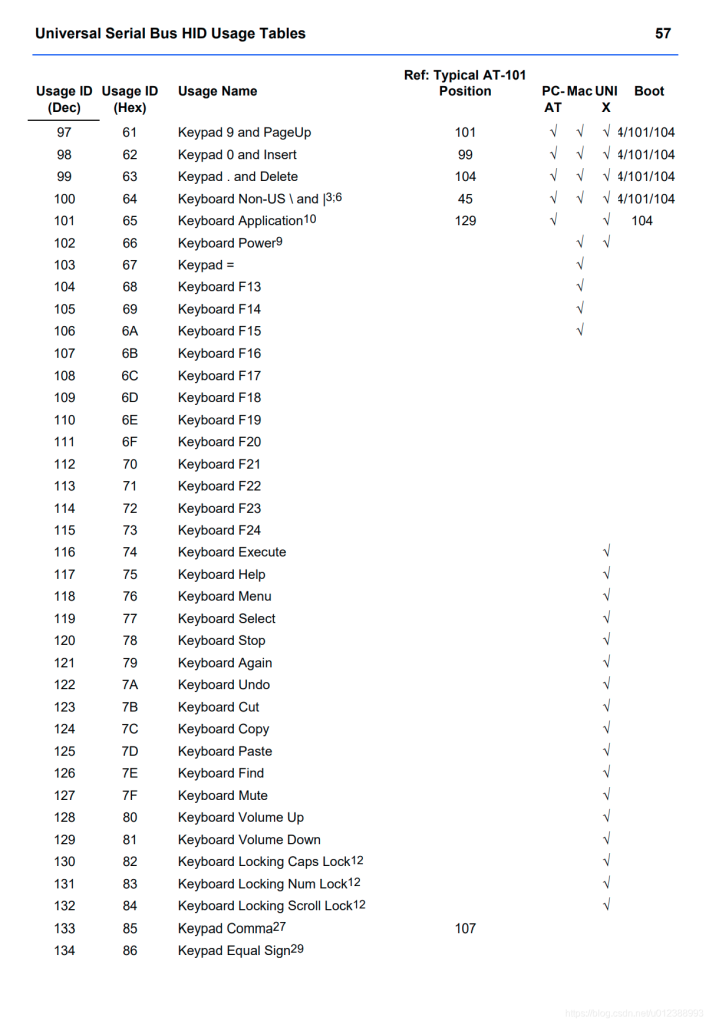
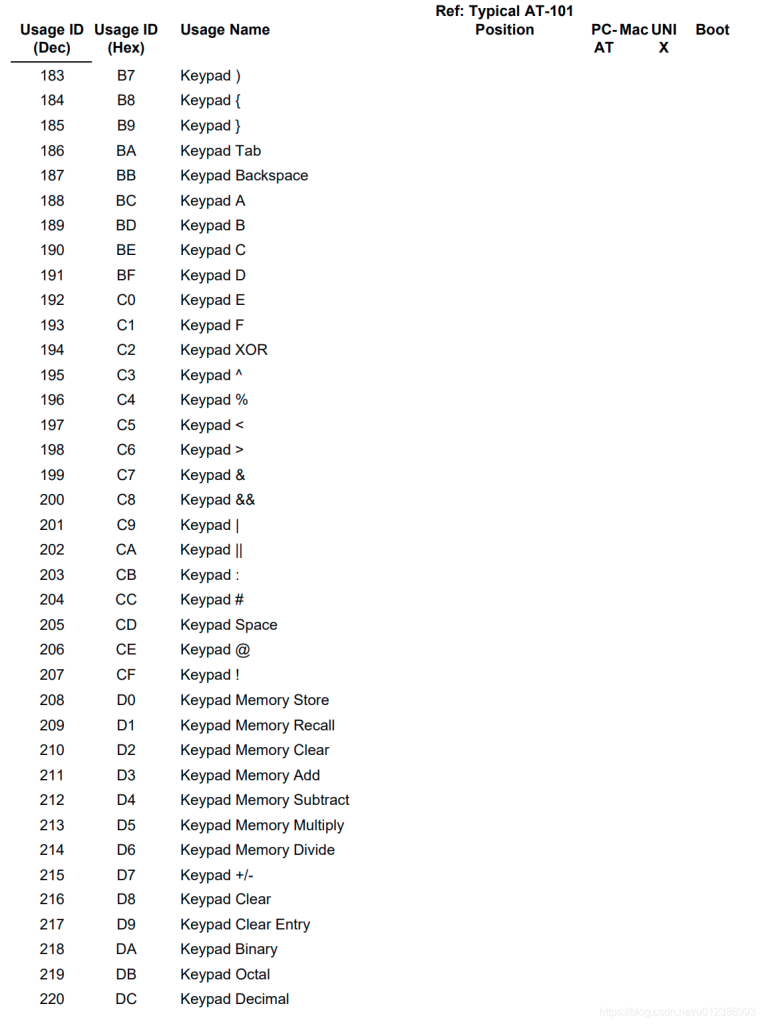
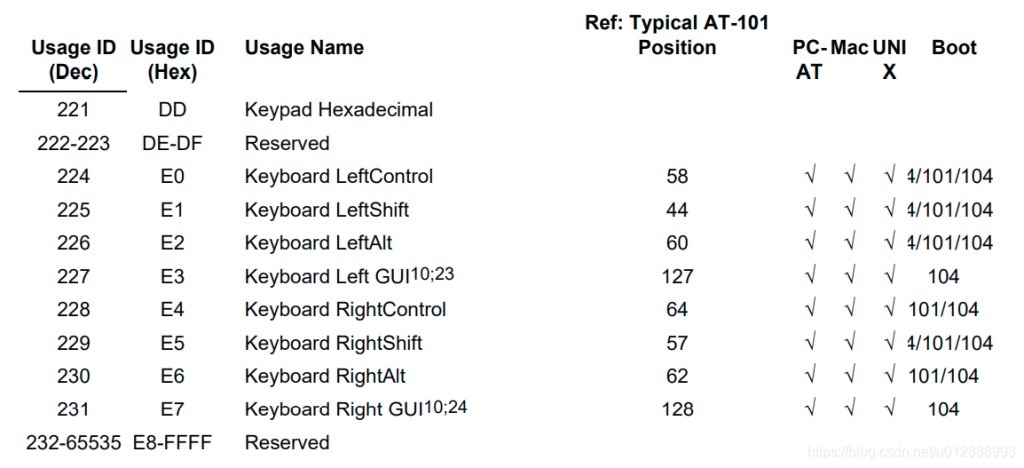
usb keyboard映射表:
USB协议中HID设备描述符以及键盘按键值对应编码表
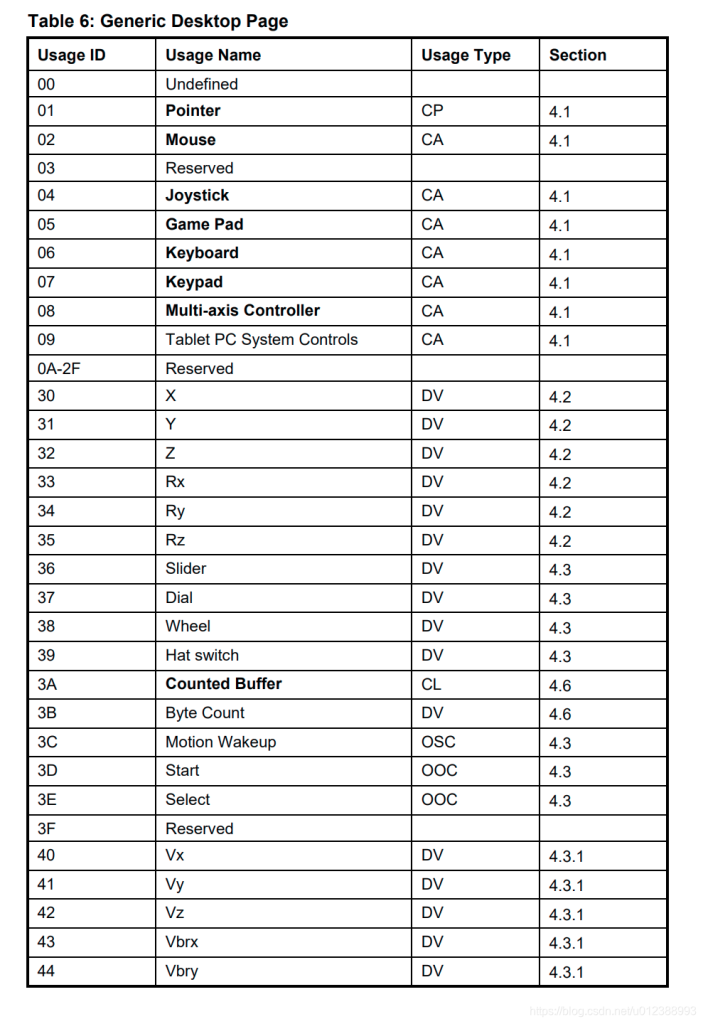
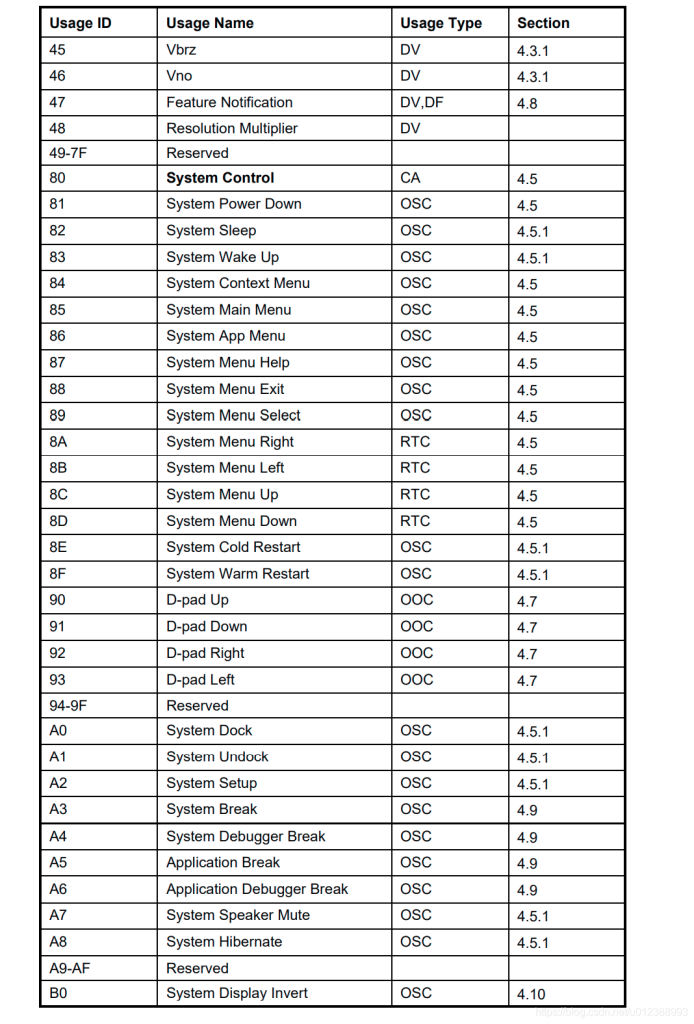
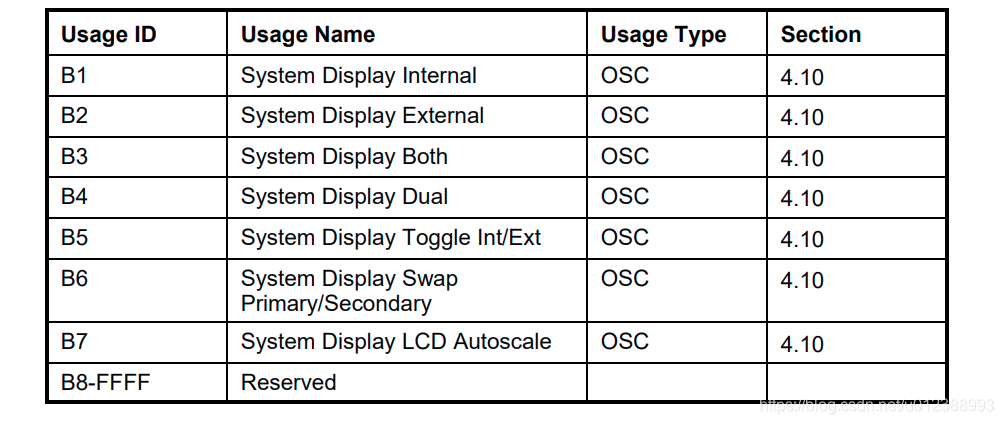
按键键值
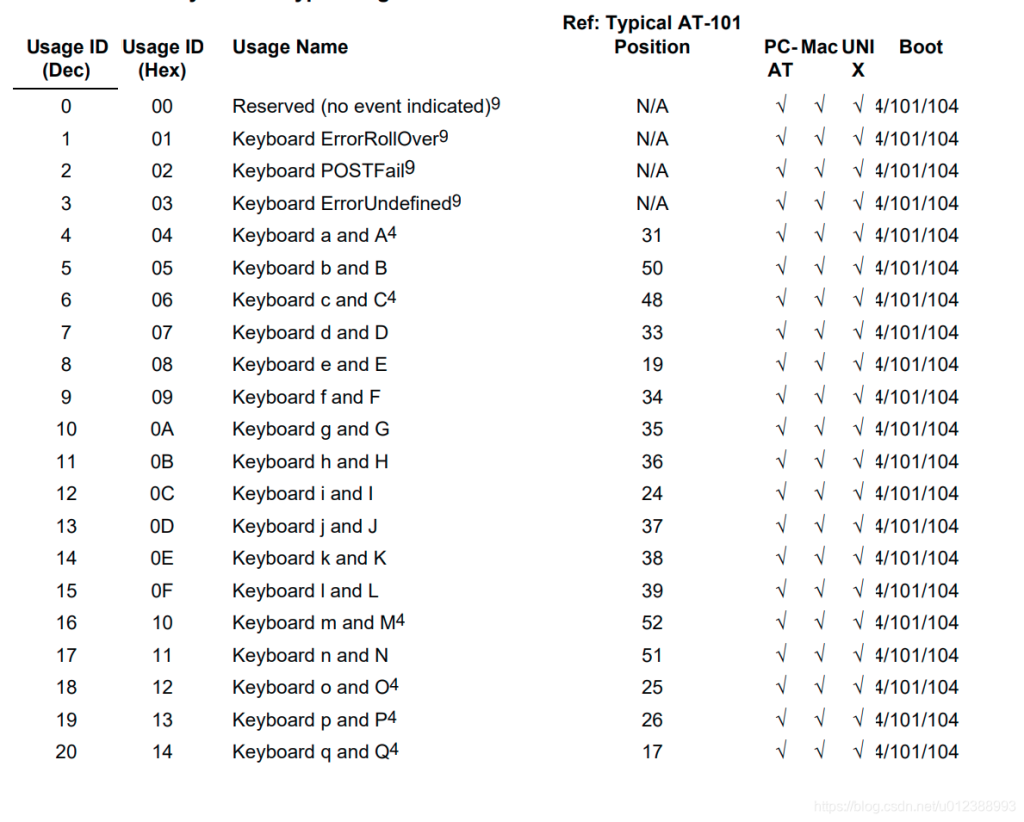
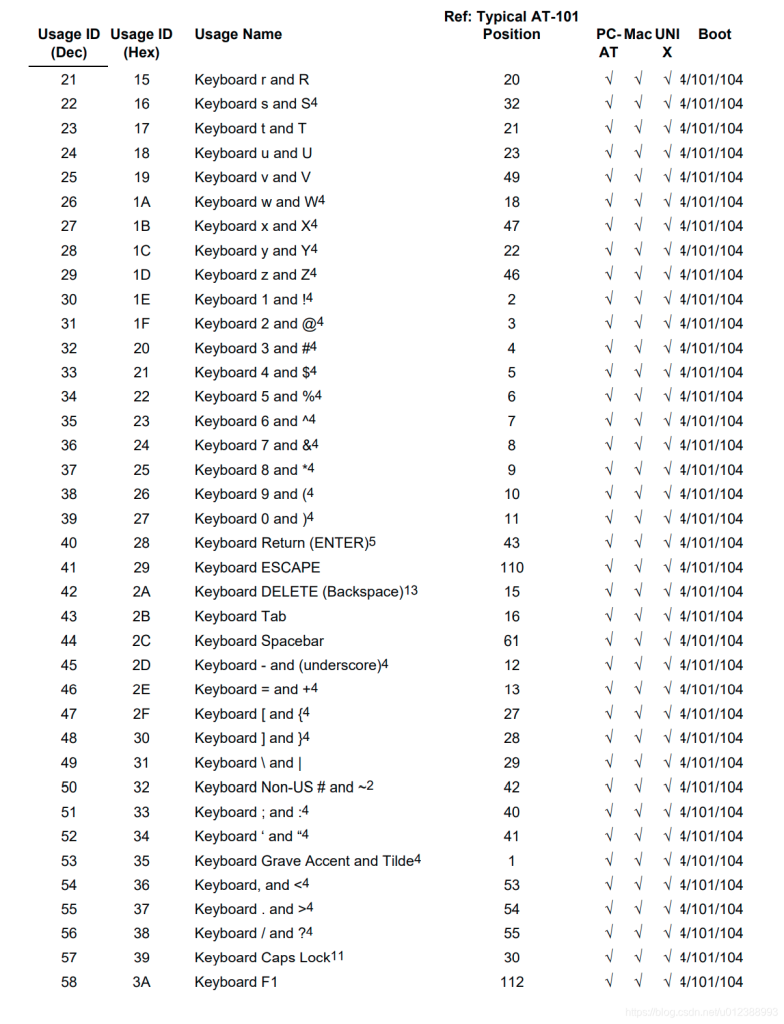
Comments NOTHING